

Can AI really solve the pain points for ad hoc analytics requests?

Summary Generated by Notion AI
A lot of AI data science/analytics tools aim to address pain points in the workflow, such as ad-hoc requests. These tools generate queries based on learned patterns and verified queries, offering a faster way to get answers. However, it is important to consider aspects like query accuracy, balancing the burden on data scientists, updating verified queries, controlling tool abuse, answering "why" questions, integrating with existing tools, and guiding cross-functional partners to ask good questions. Existing query engines, like notebooks, have accuracy and tool adoption advantages but need to address project management and ease of use for non-technical users.
Generative AI has been the center of hype this year. There are certainly some pain points in the current data science/analytics workflow that could benefit from it.
For example, everyone in this field knows that ad-hoc requests are one of the biggest headaches for data scientists/analysts. The current workflow usually involves a cross-functional partner, such as a marketing or sales teammate, who has a specific question they want to answer, like identifying the top used features by a certain customer. They will then make a post in Slack or other communication channels used by the company, specifying the exact request, its priority, and why it is important, and then wait for data scientists/analysts to triage the asks.
Data science/analytics teams are not big fans of these ad-hoc requests because they tend to disrupt existing priorities, can be repetitive (with only minor differences between questions), and sometimes have a very low return on investment, such as investigating why a trend went up or down last week. Conversely, the team making the request may become frustrated waiting for a data scientist/analyst to have the bandwidth to help them out.
To tackle this problem, numerous analytics tools powered by AI have emerged with the goal of addressing these challenges.
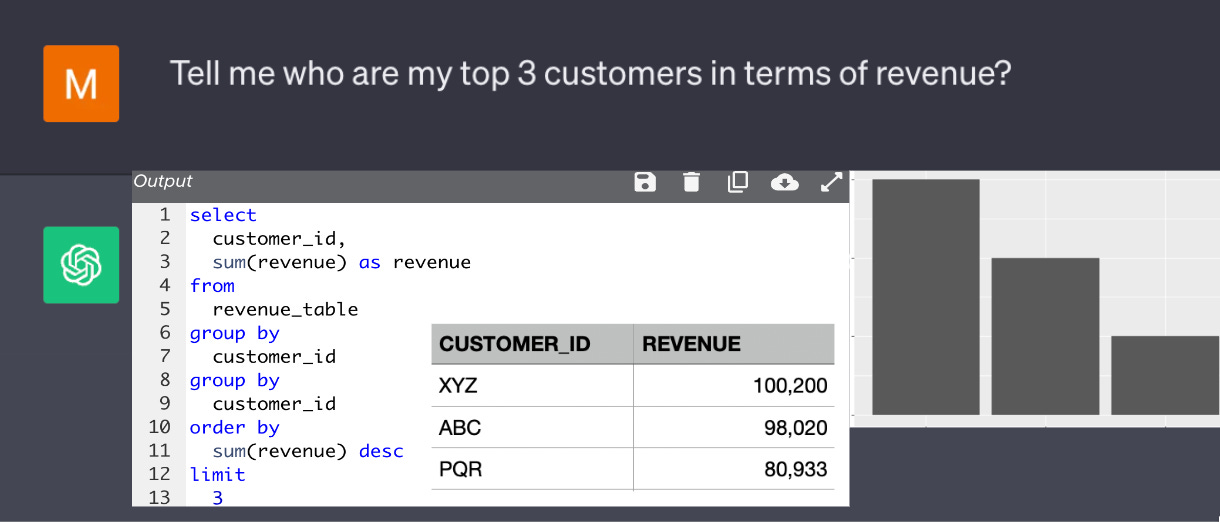
I have seen the demos and memos of 7 of these tools. Most of them have a similar Chatbot-like interface, but only one product is attempting to optimize the existing Slack workflow. When you ask a specific data science question, such as "Give me the top 3 customers in terms of revenue," the tool will generate a query based on what the AI has learned from the existing query log or the verified queries from the data science/analytics team.
The distinguishing factors of these tools typically include the number of integrations they have with existing data warehouse and visualization tools, their mobile-friendliness, the source of their training data (overall query log or specific project/team), and whether they are tailored for a specific type of team whose data questions are unique to that team, such as marketing teams.
It sounds like a sweet win-win deal where the cross-functional partners can get the answers they want really quickly without waiting for data science/analysts, and data scientists/analysts can free up a lot of time spent on these ad hoc questions and focus on more technical and ambiguous challenges. And the AI can automatically generate queries for the data scientists, simplifying the query creation process.
However after speaking with several founders of these tools, I found that many didn't realize that the product they are building is a wiki for data queries and a project management tool for data scientists/analysts. As a result, some of these tools may over-focus on addressing pain points for cross-functional stakeholders but forget that the tool's effectiveness relies on leveraging both AI and the domain expertise of data scientists/analysts to create an accurate and up-to-date wiki. To achieve this, it is crucial to motivate data scientists/analysts and make the tool manageable and easy to use for them.
In my opinion, for a tool like this to be successful, it needs to consider the following aspects:
Accuracy of query: The current way to resolve this is that almost all the tools have a verification process for data scientists/analysts. When a question is asked, and the query returned is not verified yet, the tool will fire a ticket for the data scientists/analysts to verify the query. Some tools would say verification is optional if they trust the query generated by AI and move fast that way. But currently, it is really hard to know whether the claimed accuracy by these tools is real without any statistics, especially given every company’s data model is at a different maturity stage.
One idea is to display the confidence score of these queries or indicate the source of the queries used to generate this new query. For example, if the query is based on multiple verified queries, it would provide more reassurance for stakeholders.
Balance of burden eased and increased for data scientists by having this tool: The way the verification process works still has the same problem as the current way of dealing with ad hoc requests - piled asks and no associated priorities. At least right now, when a cross-functional partner has an ad hoc request, the data science/analytics team would ask for a short blurb to describe why this piece of info is important, how urgent the ask is, and the ideal ETA. But if we are going to use these tools, it is even "cheaper" to give ad hoc requests to the team. And if the task filed by the tool is not integrated well with the existing task management system the data scientists/data analysts currently use, it will create an additional layer of complication in triaging these tasks. Yeah, you can argue that once the knowledge map of queries is built, data scientists are going to have an easier time, but data scientists will need more motivation for this huge upfront investment, and this is likely an ongoing burden (see the point below).
Verified query update: The nature of these tools is to build a Wiki of queries, which means the knowledge within the wiki can be outdated. For example, the data schema might alter, a data might be deprecated, the logic of calculating an active user might change, and a day of data might be lost from the data due to untraceable upstream issues. But what if all these have changed, but the verified badge for that old query hasn't yet?
Control of the abuse of the tool: As data scientists/analysts, we have all encountered some cross-functional partners who are "curious" about a data point, and we often said No to these good but unnecessary curiosities. The current tools lack a good mechanism to limit the number/type of questions cross-functional partners could ask and the potential computational cost associated with some unnecessary but large queries generated by AI. We previously had an incident where someone ran a large query for over 24 hours, which held up all the data warehouse resources and slowed down all other queries.
Answering beyond "what" questions: Most of the demos I have seen so far can only be used to answer “what” type of questions, aka there will be a definite answer to that, such as who are our top customers, but very few of them can answer a more ambiguous “why” type of question. For example, why have I seen a weird dip in my trend, which is a common question we get all the time.
Integration with/replacement for existing tools: On one hand, this is a common issue of many AI apps - they are siloed apps not easily integrated with existing workflows (not an advertisement, but I love using Notion AI because it feels so natural to use when I am writing in Notion). So even if the tool claims that it can help data scientists/analysts more easily write their queries, they still need to open 2 apps and copy-paste the query generated from this tool to another query interface, such as a notebook. Also, all these tools can learn the data schema through AI and have a dictionary for every data in the database. But how does this compare to existing schematization tools that the team has already invested in? Additionally, the charts generated are powered by some open-source tools like Superbase, which are different from the charts data scientists/analysts generated themselves and lack customization capability.
Guide for cross-functional partners to ask a “good” question. Initially, the questions asked by cross-functional partners serve as the foundation for the query wiki. Once the wiki is created, these questions should efficiently and accurately guide them to the desired information they are looking for. Often, when our cross-functional partners ask data scientists/analysts a question, we may need to ask follow-up questions to clarify their request. For instance, we might need to ask them what exactly the time frame they are looking for or determine if certain user types should be excluded from the results. Having a tool that provides cross-functional partners with good prompts to allow them to specify the data requests would streamline their thought process and minimize the need for back-and-forth communication.
Additionally, since it is a query wiki, it should provide a simple way for data scientists/analysts to create the wiki while working on their queries. For instance, an AI can suggest a simple tag every time a data scientist successfully runs a new query, indicating whether the query is eligible to be added to the wiki and which domain it belongs to. This would make it easier for them to build the wiki as part of their daily work, increasing the likelihood of tool adoption without the need to constantly refer back to old code to add a verified answer.
I strongly believe that existing query engines, particularly notebook tools, have an advantage in addressing the challenges of query accuracy and tool adoption more effectively than standalone tools. This is because data scientists and analysts already use notebooks or worksheets in their work, unless these new products can seamlessly integrate with those query engines. By learning from established projects, AI can more easily understand the logic and generate more accurate queries based on that knowledge. On the other hand, data scientists can leverage the power of AI to reduce the time spent on query writing and create charts with the same aesthetics. However, the challenge for those query engines lies in understanding the project management aspects of this tool and making it easily adoptable for non-technical individuals, especially those who are unfamiliar with the Notebook structure.